Resiliency, partitioning, and dependence
Our intent in this round is to focus on what can perhaps be described as easy scaling from a single node to a cluster of nodes.
That is, our intent is to benefit from high-level cluster computing abstractions that enable us to (almost completely) relegate the nitty-gritty details of low-level cluster management such as circumnavigating around node faults to the underlying processing engine, which in our case will be Apache Spark.
A first step in this path is to understand the key concepts and principles related to cluster computing with large amounts of data. These include resiliency, partitioning of the data to the nodes, transforming the data, and the dependencies that arise in the process. Again the functional programming model will provide to be convenient. In fact, programming with Spark feels like programming with ordinary Scala collections. The main difference is, of course, that the “collection” (the resilient distributed dataset) is actually distributed across the nodes of the cluster.
What can be computed in a computer cluster?
A cluster is a network of computers. Even if our programming abstractions try to shield us from the hurdles of working with a network of nodes, the abstraction can do absolutely nothing to alleviate the inherent physical constraints of such an arrangement. Let us review a few such constraints.
First, the network connecting the nodes has limited bandwidth. If our computations require that the network nodes communicate extensively with each other, we should be prepared for network congestion.
Second, even if there is no congestion and even at the speed of light, it takes time to communicate over a network. (Remember that the typical clock cycle length of a modern CPU is less than one nanosecond. Light travels about 30 centimeters in one nanosecond.) Thus, communication latency is an issue if we require exchanges between nodes for our computations to proceed.
Third, if we distribute a large dataset across the nodes of a cluster, it may be that the dataset does not fit in main memory (RAM) at the nodes. This means that we need to use secondary storage such as SSD or disk, which introduces further processing delays.
Fourth, an individual node is a fairly reliable device. A cluster with a thousand nodes is not. Entire nodes and components at the nodes fail during normal operation, and we should prepare for failures.
Given the constraints above, it is immediate that not all computations scale up from a single node to a cluster, at least not with the speedup and programming ease that we would like to obtain. Yet programming frameworks such as Apache Spark are great tools for processing massive amounts of data, as long as our processing needs are restricted to specific types of transformations on the data. Before proceeding with a detailed review of these transformations, let us develop a rudimentary view of cluster computing.
Remark. (*) A reader interested in a less rudimentary treatment of warehouse-scale computing is recommended to consult Barroso et al.
Driver node and worker nodes
A common way to set up a computer cluster with multiple nodes is to designate one node as the driver node that controls the operation of the other nodes, which are called worker nodes. All the nodes are joined by a network. (We will disregard all details of the network infrastructure.)
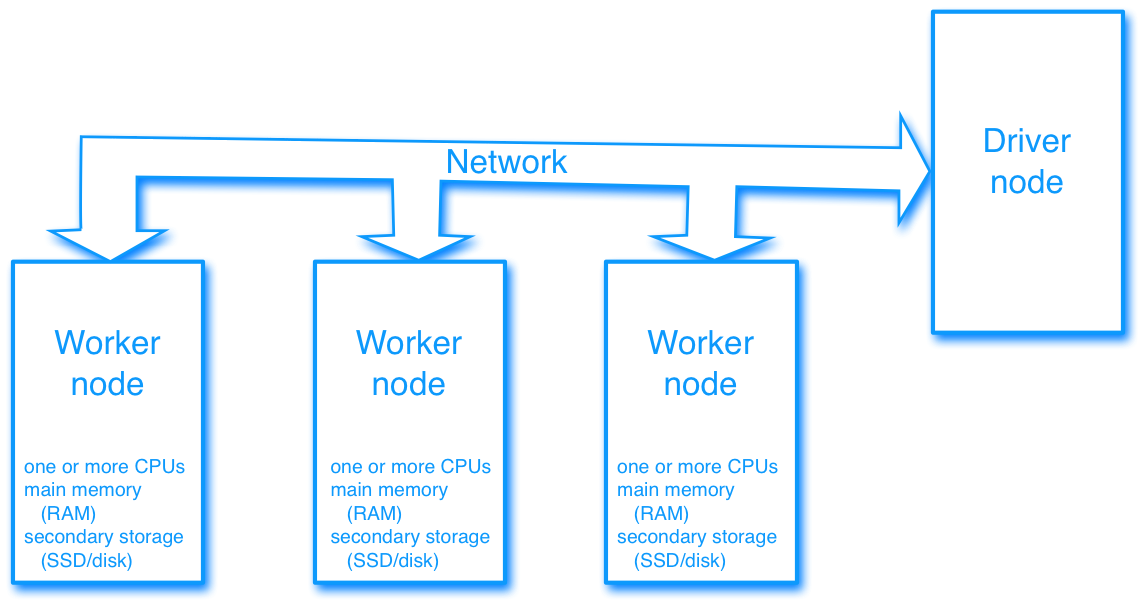
Each worker node has its own compute resources consisting of one or more CPUs, local main memory (RAM), and local secondary storage (SSD or disk). Also dedicated graphics processing units and other local resources may exist at the nodes.
The driver node allocates tasks to the worker nodes. Data and programs are loaded to the worker nodes from the driver and from network storage. (Network storage is typically used only initially to load data into the cluster. Once the data is loaded, the workers compute using their local resources, communicating with each other as necessary.)
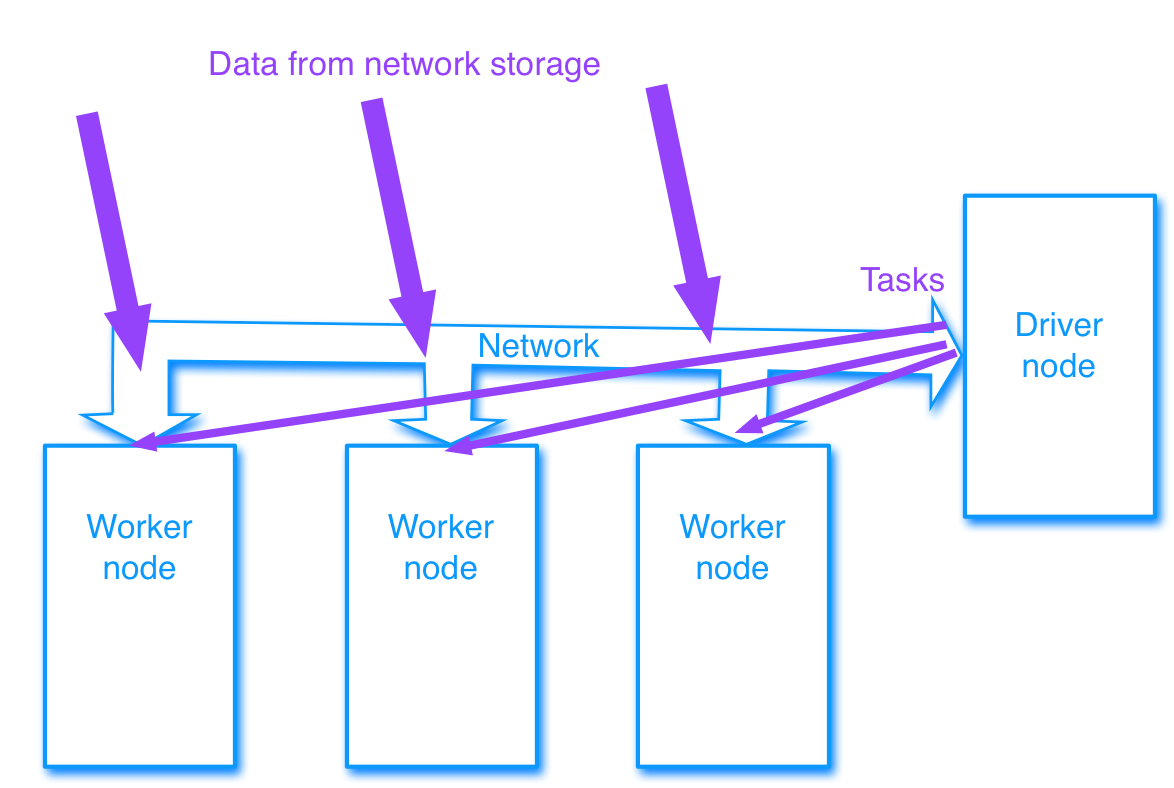
Once the allocated tasks are finished, the driver either proceeds to allocate more tasks, or proceeds to collect the results from the workers, who will then report back to the driver with their results, or save their results to local storage. (Also network storage may be used, but typically only when all the work is finished.)

Hardware failures and resiliency
With sufficiently many nodes in a cluster, node failures occur regularly. Such failures typically occur at the worker nodes since there are far more worker nodes than driver nodes. (In fact, it may be that there is only one driver node, which may mean in practice that our entire computation is lost if the driver fails.)
Once a node failure is detected, a common strategy is that the cluster management system allocates a new node to replace the faulty node, which is then put to work by the driver node. The memory contents and the local secondary storage at a failed node are typically irrevocably lost, which means that the driver must recover the lost data using the data available at other nodes and/or network storage if computations are to proceed as if a failure never happened. In practice such resiliency (or fault-tolerance) against a limited number of failures is built into the programming framework (such as Apache Spark) and into the underlying software stack, in particular the file system (such as HDFS).
Partitioning and persistence (*)
Already from our rudimentary perspective to cluster computing, it should be apparent that it matters a great deal from a performance perspective how our data is partitioned into the cluster. If most of our data is only at a handful of nodes, the performance we get is far from optimal. Similarly, we should strive for narrow dependencies to avoid network congestion.
A yet further dimension to performance occurs with the use of local resources at each worker node. If possible, we should persist (cache) our data in main memory at the workers to enable fast, local transformations.
Remark. (*) A reader interested in going beyond our rudimentary description as regards performance aspects and resiliency is encouraged to consult the Spark Documentation and the paper presenting the RDD abstraction implemented in Spark. (*)