Resilient distributed datasets
The main programming abstraction in Apache Spark is a (Resilient) Distributed Dataset (an RDD for short) that represents a dataset distributed across the (worker) nodes of a cluster. If we forget about performance considerations, we can pretty much view an RDD as a regular Scala collection.
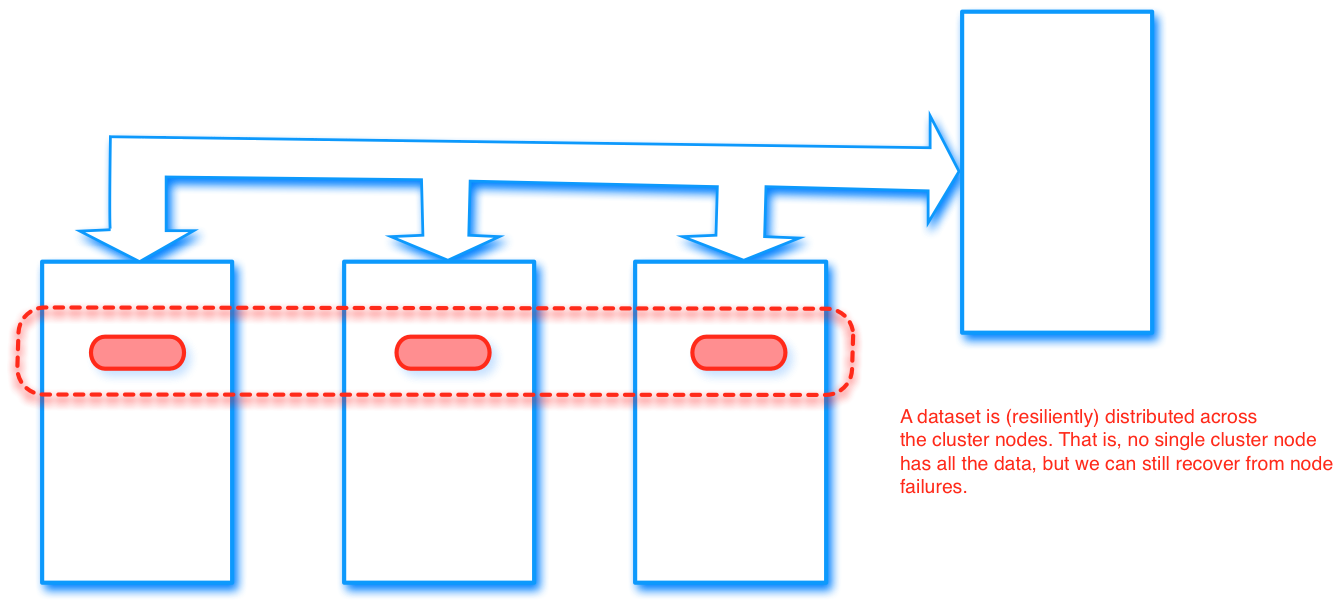
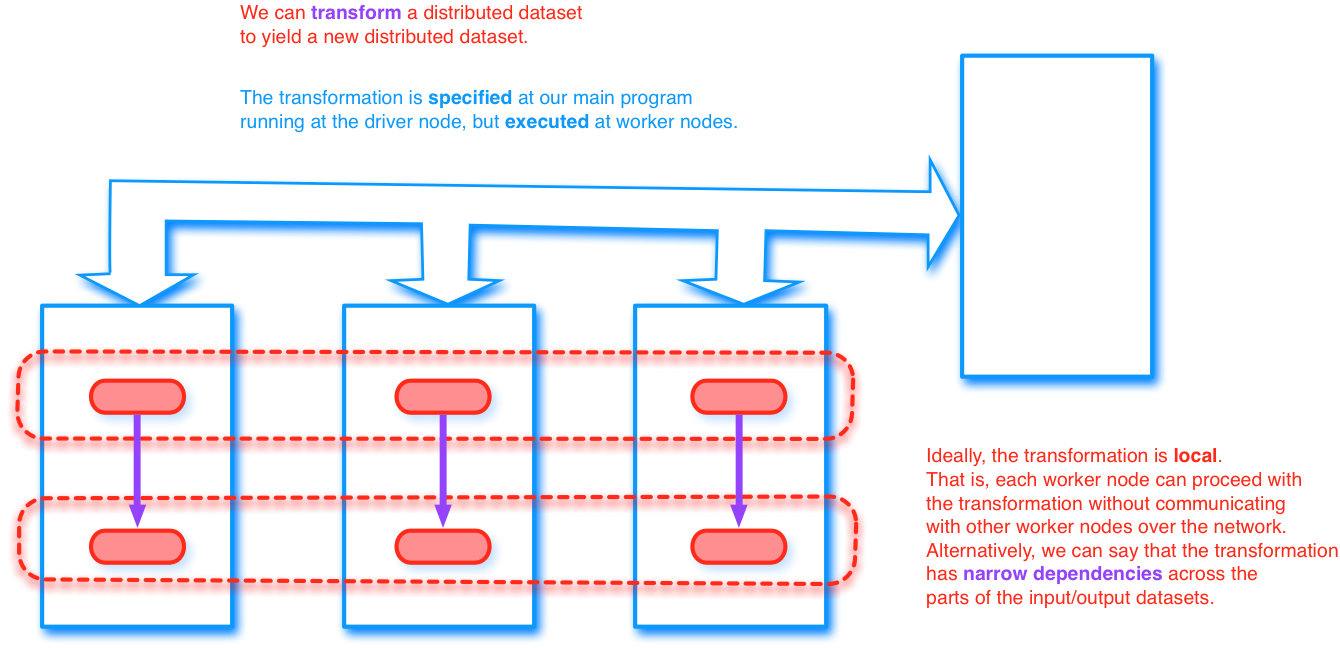
When we program with Spark, it is important to understand that our program runs on the driver node, but the transformations that we specify on an RDD are executed by the worker nodes.
Ideally, a transformation is local (or has narrow dependency across the parts of the input/output datasets). That is, each worker node can proceed with the transformation without communicating with other worker nodes over the network.
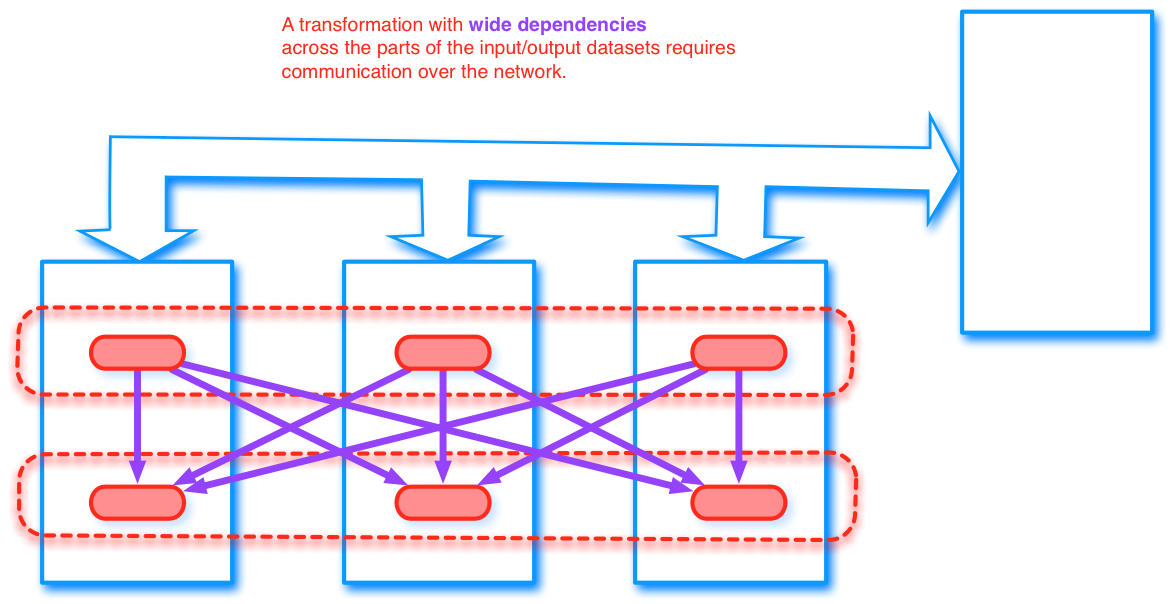
A transformation with wide dependency across the parts of the input/output datasets requires communication over the network.
Transformations on RDDs
To a reader familiar with functional programming and collection abstractions, the following table of RDD transformations (from Zaharia et al.) should be fairly self-explanatory. Perhaps a few remarks should be made though.
Remark 1. The transformation is specified at the main program running at the driver node but executed at the worker nodes. Accordingly, all the function parameters to the transformations should be pure functions so that the closure can be serialized and transported from the driver to the workers over the network.
Remark 2. The partitioning of the RDD affects whether a transformation has narrow or wide dependencies. For purposes of solving the present exercises we will be running Spark locally on one node, so this does not matter a great deal from our present perspective. Accordingly we will leave out a detailed consideration of partitioning. (An interested reader can consult the remarks above.)
Remark 3. Observe that many transformations operate only on RDDs whose
elements are tuples of type (K,V). These transformations assume that
the object of type K in each tuple is the key by which we group,
reduce, join, sort, and so forth, the actual content of type V.
Remark 4. For detailed examples and use cases for each transformation, consult the Spark RDD programming guide and the Spark RDD API.

Actions on RDDs
Observe that the table above also contains actions that we can perform on an RDD. Actions instruct the worker nodes either
to save the data in the RDD (for later processing), or
to send data to our main program (that runs in the driver node).
For example, if the RDD has only a few data items (typically this is the case if the RDD is the result of a number of transformations that have narrowed down the original input data), we can collect the data from the RDD to a local Scala collection in the main program. Alternatively, we can also reduce the data or perform lookups by individual keys to keyed data.
Remark. For detailed examples and use cases for actions, consult the Spark RDD programming guide and the Spark RDD API.
Next step: Try it for yourself
Now you have a brief introduction to the idea behind Apache Spark and RDDs. The next step is to see some examples of Scala code using Spark. For this, we recommend that you look at the source code for the first programming exercise for this round, which contains a short, but complete program. Read this and note the steps taken to set up a Spark Context, initialize the work, and collect the result.
You may also want to look at the API documentation for Spark and the API for RDD Class in particular.
Note the presence of methods such as map, flatMap, count, etc. Programming abstraction hides the concurrency and provides the same interface to transformations and actions as we have seen for Scala’s standard collections and parallel collections.