|round-pfx:virtualization-scalability|: Virtualization and scalability
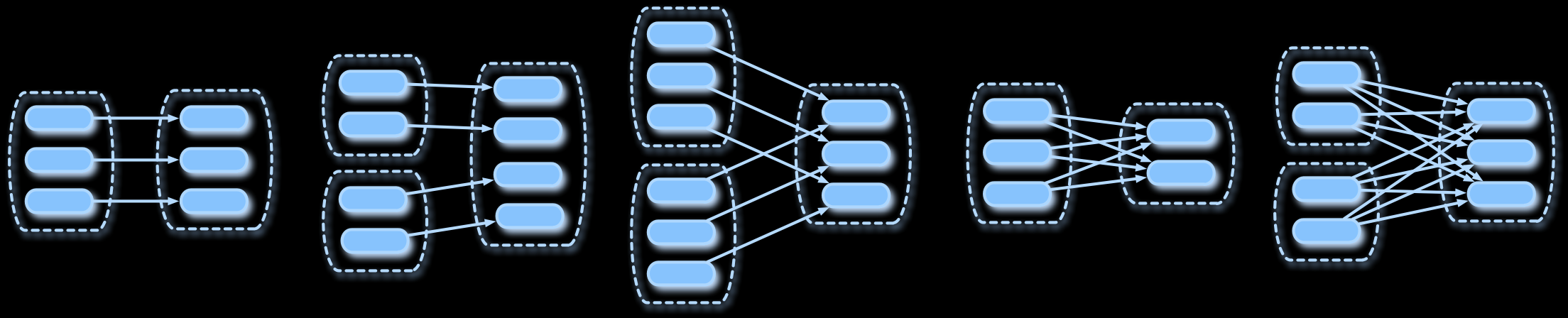
(Narrow and wide dependencies between partitioned datasets.)
Learning objectives
In this round you will learn …
… that computing resources are an available-on-demand, low-cost, bulk commodity
… that easy programming abstractions exist to enable scalability to
warehouse-scale computers (WSCs) with tens of thousands of nodes, and
extremely large, distributed datasets
… that WSCs form the infrastructure that implements basic services on the Internet
… that large-scale infrastructure routinely experiences hardware failures
failures that happen during a computation are too laborious to correct manually
the programming abstractions must be resilient to failures (fault-tolerant)
… that functional programming scales up and provides resiliency
a resilient distributed dataset (RDD) is a collection that is partitioned across the nodes of a cluster
an RDD can be transformed using standard primitives (map, filter, reduce, group, join, …) on collections to yield a new RDD
a dependency DAG on RDDs enables transparent recovery from failures by recomputation
… to work with RDDs as implemented in the Apache Spark system
… that efficiency is obtained by paying attention to (*)
partitioning of each RDD across cluster nodes, (*)
persisting (caching) each RDD in main memory at the nodes, and (*)
dependencies between parts of RDDs in a compound transformation (*)
(Material that is marked with one or more asterisks (*) is good-to-know, but not critical to solving the exercises or passing the course.)